
Cuando me refiero a “redes” no me estoy dirigiendo tan sólo a lo que se entiende por redes sociales; una red es una formación estructural en la que un conjunto de nodos establecen relaciones entre si. Un nodo puede ser una persona, un perfil de Twitter, un aeropuerto, una estación de metro, un transformador de energía eléctrica… el estudio de las relaciones entre estos elementos, fundamentado en el álgebra de matrices, puede generar información muy útil para tomar la decisión más adecuada: por ejemplo, cómo construir un circuito eléctrico de manera que se optimice su eficiencia.

El análisis de redes, pues, extiende su campo de aplicación a ámbitos tan distantes como la informática, la neurología, la sociología… es una herramienta interdisciplinar. Siempre que se estudie algo donde existan relaciones entre elementos, tendremos una red. En ciencias sociales, el análisis de las redes puede dar respuestas a preguntas hasta ahora no formuladas o no respuestas. Se podría describir con claridad, por ejemplo, cómo funcionan las redes de apoyo cuando una persona se ha quedado en el paro.
El surgimiento de las redes sociales en internet, además, abre un gran campo de posibilidades para los investigadores, al proporcionar grandes cantidades de datos de nodos (perfiles sociales) relacionándose con otros nodos. El análisis de redes, bajo estos términos, ¿es definible mediante la palabra “Big Data”?
Centrémonos en el caso de Twitter. Desde mi punto de vista, se pueden clasificar las redes a obtener en dos grandes categorías:
- Redes estructurales: es la red que conseguiríamos si las relaciones entre nodos estuvieran cimentadas en las métricas más clásicas: friends y followers. De esta manera obtendríamos un mapa de la estructura de la caja negra en la cual fluyen los mensajes… sin embargo, poca cosa sabríamos sobre cómo estos mensajes se han, efectivamente, distribuido.
- Redes de proceso: es la red obtenida cuando ponemos el foco de atención en las conversaciones. Es decir, nos olvidamos de la caja negra y estudiamos lo que dentro de élla sucede… algo más interesante, quizás, que el análisis de uns simple red estructural. Si tengo 1.000 followers, es muy probable que mi mensaje llegue a muchos otros perfiles; pero nadie me lo asegura. Una mejor aproximación a este problema consistiría en analizar conversaciones reales.
¿Qué entendemos, sin embargo, por conversaciones reales? En Twitter, se produce comunicación cuando un usuario menciona a otro en uno de sus tuits. Cuando esto sucede, el emisor está llamando la atención al receptor para que éste conteste una pregunta o dé la opinión sobre algún comentario.
Procediendo así, nos aseguramos que, con gran probabilidad, el receptor habrá podido interpretar el mensaje, cosa que no es posible a través de un simple análisis estructural (es poco probable que el mensaje llegue a tus 1.000 seguidores si, cada uno de ellos, sigue a 1.000 perfiles más). El hecho que el receptor responda o no al comentario poco importa; consideramos, en este caso, que la comunicación está siendo unidireccional, dirigida. Pese a que la respuesta es un buen símptoma de que, efectivamente, se ha producido comunicación, la no respuesta no implica necesariamente que no se haya establecido una relación entre emisor y receptor.
Un caso aparte es el que se presenta cuando analizamos los retuits… un retuit en el que se menciona al perfil emisor no indica una intención expresa de iniciar una conversación. Más bien pretende dar difusión de un hecho u acontecimiento que ha sido considerado como interesante por parte del emisor del retuit. Pero es obvio, debido a su gran poder de difusión, que los retuits construyen y rearticulan las conversaciones que se están sucediendo en Twitter. Veamos un ejemplo extraído de un estudio publicado sobre las conversaciones generadas en Twitter alrededor de un programa de televisión:

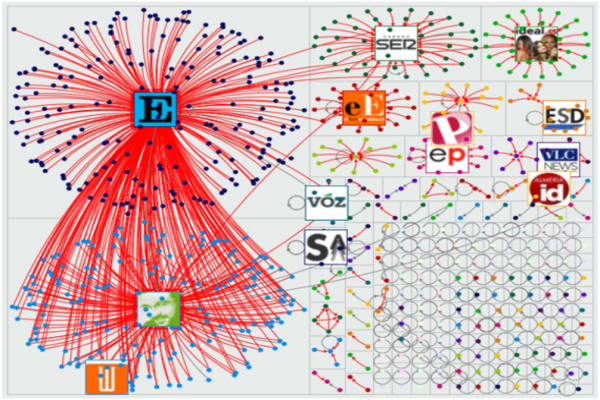
El gráfico hace referencia a la extracción de una muestra de las conversaciones generadas hasta un día después de la emisión del programa Operación Palace, que provocó el enfrentamiento de dos posiciones distintas: la favorables a la “moraleja” que pretendía dar su autor, Jordi Évole; y los contrarios a utilizar un falseamiento de la historia, sea cual fuere la intención con la que esto se hacía.
Los puntos (nodos) son perfiles de Twitter. Una línea finalizada con una flecha significa que el usuario ha mencionado, en alguno de sus tweets, al receptor de dicho mensaje. Si la línia es roja (la inmensa mayoría de éllas) indica que se trata de un retuit.
Vemos, también, que los nodos se organizan al interior de pequeñas cajas. Los grupos de puntos en cada una de estas cajas indican cierta afinidad de los nodos que contiene en cuanto a sus características de relación interna. Es decir, para segmentar los nodos de la red se ha seguido un procedimiento parecido al del análisis de clasificación, con la diferencia que la distancia empleada no ha sido la euclídea sino la distancia entre nodos (saltos que debe dar un nodo para llegar a otro nodo).
Cada caja, pues, muestra la configuración de un grupo de comunicantes cuyas relaciones se establecen, básicamente, en el si del propio grupo. Como no podía ser de otra manera, el análisis de redes se realiza en base a métricas. Para introducir alguna: la modularidad de esta red toma un valor de 0,52 (en una escala que va del -1/2 al 1). Esto significa que los grupos generados superan el número de relaciones esperado en el caso que la red se hubiera formado por puro azar y que, por lo tanto, no nos equivocamos al afirmar que estos grupos tienen una existencia real y propia.
Cada uno de los grupos presenta un nodo central: esto no es algo siempre habitual en el análisis de redes, sino que es el resultado propio de un análisis conversacional en el que intervienen los medios de comunicación de masas (que fueron los que, al final, dieron alas al debate). Cada medio de comunicación dio su propia versión sobre la noticia y ésta fue retuiteda por sus consumidores. Es por esta razón que el color predominante en la representación de las relaciones es el rojo.
Uno de los nodos centrales, sin embargo, no es un medio de comunicación. El componente de abajo a la izquierda, en el que los nodos son de color azul claro, tiene a Jordi Évole como epicentro. Es lógico teniendo en cuenta que él, y su programa, fueron el foco de atención del del debate. En este componente de la red, algunos tweets alababan el programa realizado por Évole. Sin embargo, la mayoría eran re-tweets que mencionaban, al mismo tiempo, tanto a @jordievole como al diaro @elpais. Es por esta razón que hay tantas líneas que van desde el componente de @jordievole al del @elpais.
Y aquí viene el segundo componente: arriba a la izquierda se puede observar como el nodo central es el de El País. Entre algunos de los artículos que se publicaron el día siguiente, destacó uno, por su capacidad de difusión: “Évole bate récords por su patraña del 23F”. Este mensaje se difuminó entre el flujo conversacional llegando a gran parte de la red… no sé hasta qué punto influyó la visión de El País sobre la formación de la opinión pública (concepto, muy a menudo, vacío de contenido…), pero lo que sí se pude saber es que, al menos, su mensaje llegó.
Curiosamente, en el resto de componentes o subgrupos encontrados en esta red, se observa una total preponderancia de los medios de comunicación progresistas o liberales… más o menos próximos a la ideología de Jordi Évole. A tenor de esta información, se podría concluir que los que alimentaron el debate fueron medios afines al propio Évole. Es lógico: seré más propenso a dar mi opinión si sé de qué trata el debate. Será más probable, por lo tanto, que opine si estoy entre los telespectadores habituales de Salvados. Y también, sólo a nivel de hipótesis, se advierte que es muy probable que el target al que se dirige Jordi Évole sea mucho más propenso a utilizar Twitter…
Otros de los medios que contribuyeron a impulsar el debate, aunque con menos fuerza que El País, fueron la Cadena Ser, el diario Público, el diario El Economista o Voz Populi. La gráfica que representa cada uno de estos grupos encaja con el patrón de Broadcast Network que se describe en este artículo de Pew Research, en el que “muchas personas repiten lo que es prominente en los medios de comunicación”.
Sin embargo, cada uno de estos medios de comunicación no tiene una existencia totalmente aislada del resto de nodos de la red. Algunos perfiles de Twitter sirvieron de puente para enlazar contenidos de dos o más medios de comunicación. Son perfiles, por lo tanto, que, pese a poder tener pocos followers, han tenido una importancia capital en la articulación de la conversación. El número de seguidores, pues, no es un elemento definitivo para poder afirmar que un determinado mensaje se convertirá en viral. Conseguir que un mensaje sea viral depende, más bien, de una siembra aleatoria e indiscriminada de un mensaje a todos los nodos que conforman la red.
Éstas son tan sólo algunas de las ideas que se pueden extraer del análisis de redes, una técnica que permite describir y sintetizar una gran cantidad de datos en un simple gráfico. La complejidad matemática a la que se puede llegar mediante este tipo de análisis es inalcanzable a través de un único post, con lo que aquí nos detendremos en la exposición. En próximos posts analizaremos con más profundidad cuáles son las posibilidades, y también los límites, del análisis de redes.
Fotografía 1: sjcockell
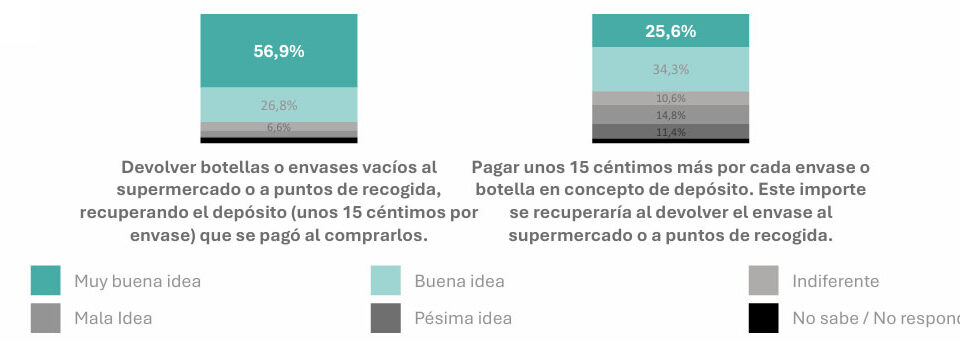

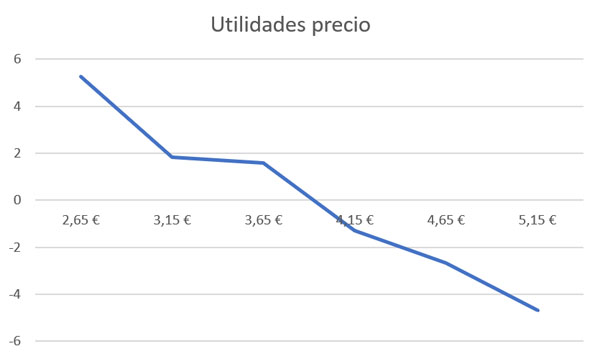
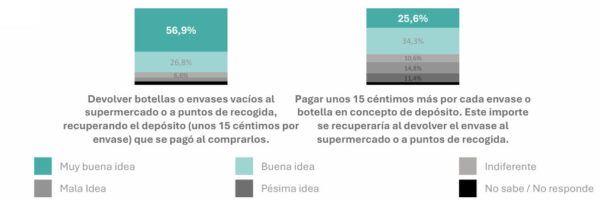{kind=link}
{kind=link}