

Ahora que ya sabes cómo preparar el archivo de datos del conjoint (puedes ver cómo hacerlo en este otro post), te explicaremos cómo procesarlos a través del módulo de R ChoiceModelR.
Antes que nada, asegúrate que tienes instalados los siguientes paquetes de R: “bayesm”, “MASS”, ”lattice”, ”Matrix”, ”ChoiceModelR” y “XLConnect”. En la web encontrarás muchos tutoriales sobre cómo instalar paquetes de R… aquí te dejamos un ejemplo.
Asegúrate también que el csv que vas a cargar esté en el directorio de trabajo de R. Y aquí tienes el código que tienes que introducir en la consola de este software para proceder con el análisis:
library(bayesm)
library(MASS)
library(lattice)
library(Matrix)
library(ChoiceModelR)
library(XLConnect)
path_cwd <- getwd()
data<-read.csv( ”conjoint.csv” ,
sep=”;”,
header = TRUE)
# set parameter for calculation
R = 20000 #Total Iterations of the Markov Chain Monte Carlo
use = 2000 #Iterations for Paramerter-Estimation
# Parameter of datainput
none = TRUE #TRUE, if the questionaire has a none-Option but is not coded in the data
xcoding = c(0,0,0) #0=nominal scale; 1=metric scale
#Parameter dataoutput
save = TRUE #TRUE saves the calculated parameters
keep = 5 #number of random parameter draws to save (thinnig Parameter)
mcmc = list (R=R, use=use)
options = list(none=none, save=save, keep=keep)
#final calculation of the betas
out = choicemodelr(data, xcoding, mcmc=mcmc, options=options, directory=path_cwd)
Solo tienes que sustuir los caracteres marcados en rojo por lo que corresponda a tu caso. En “data”, simplemente escribe el nombre de tu fichero de carga. En “xcoding“, introduce tantos ceros como atributos tenga tu diseño de conjoint. Hay otras opciones que permiten customizar tu análisis, que puedes consultar en la documentación del paquete, pero con esta base ya tendrás suficiente para seguir adelante. Por ejemplo, si tienes pensado que otras personas puedan replicar tu metodología, no sería mala idea guardar la semilla a partir de la cual arranca tu análisis. Cada análisis que hagas, debido a cierta aleatoriedad existente en los cálculos, te dará resultados ligeramente distintos. Guardando esta semilla te asegurarás de que otras personas que repliquen el análisis obtendrán exactamente el mismo resultado.
Una vez hayas introducido este código en la consola, dale al intro… y la magia empieza.
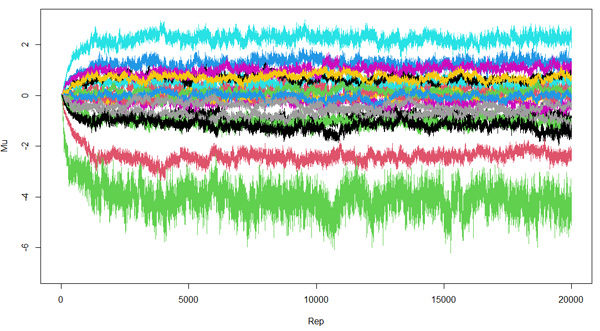
En primer lugar, verás que se te abre una ventana con este gráfico, que irá evolucionando a medida que se desarrolle el análisis. El algoritmo de cálculo inicia con la primera iteración (una muestra de los parámetros que pretende calcular el modelo). Los resultados de esta primera iteración servirán de base para realizar una segunda iteración (otra muestra de parámetros) y así sucesivamente, hasta llegar a las 20.000, que son las que teníamos predeterminadas en nuestro código. El hecho que iteraciones pasadas sirvan de base para calcular iteraciones futuras explica por qué el modelo aplicado por ChoiceModelR tiene un enfoque bayesiano.
No hay que establecer obligatoriamente las 20.000 iteraciones. La idea es jugar con un número de iteraciones suficiente para que las líneas del anterior gráfico, que representan las utilidades de cada uno de los niveles de nuestro conjoint, se estabilicen o converjan.
De otro lado, verás que la consola de R, a medida que se va desarrollando el análisis, muestra los siguientes resultados:
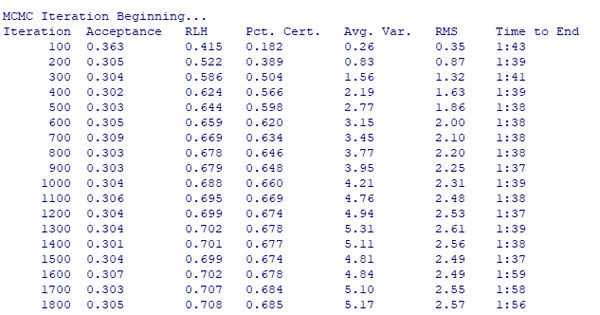
Cada 100 iteraciones ChoiceModelR te muestra los resultados a los que, hasta el momento, ha llegado el modelo. Aunque ofrece varias métricas, la realmente interesante es la de RLH (Root-likelihood), que, tomando valores del 0 al 1, indica cómo de bien un modelo se ajusta a los datos. Cuanto más se acerque a 1, más capacidad explicativa tendrá el modelo. Verás que, para cada iteración, el RLH va aumentando, hasta llegar a un punto en el que una nueva iteración ya no hace cambiar su valor de manera significativa. Es aquí cuando habrás llegado al punto de convergencia.
En el caso que nos ocupa, nuestra iteración 20.000 presenta un RLH de 0,73, indicando un buen ajuste del modelo a los datos. Si el RLH de tu modelo indica un mal ajuste… lo más probable es que hayas diseñado el conjoint de manera errónea.
Más allá de de la información que muestra la consola de R, ChoiceModelR guardará 4 ficheros en tu directorio de trabajo. En el siguiente post te hablaremos del fichero RBetas, que es el que realmente nos interesa para seguir con nuestro análisis Conjoint.
Add comment